PROGEDO-Loire a accompagné une doctorante du laboratoire TEMOS dans la réalisation d’une base de données relationnelles avec LibreOffice Base.
Comment s’est construite l’expertise semencière internationale depuis le XIXe siècle ? Quelle a été sa temporalité ? Qui en étaient les acteurs ? Quelles tensions s’exprimaient entre les logiques nationales intrinsèques aux stations nationales, et la dynamique internationale prônée par ces structures qui s’organisent en une association dès 1921 ?
C’est en voulant répondre à ces questions qu’Anaïs GOT a entrepris le dépouillage exhaustif des comptes-rendus de l’Association internationale des stations d’essais de semences[*], qu’elle appelle les PISTA (Proceedings of the International Seed Testing Association). Cette source contient des articles scientifiques, des informations relatives à la vie ordinaire de l’association (comme les membres ordinaires et les membres des comités) et à la vie extraordinaire de l’association (par exemple, les participants aux différents congrès).
L’historienne souhaite notamment questionner :
- les thématiques abordées par les PISTA (thématique des articles, des comités, des congrès) ;
- le profil des acteurs mentionnés dans les PISTA : leur genre ; leur nationalité ; leur nature (comme : auteur, membre d’un comité, participant à un congrès) ; le type d’établissement d’appartenance ; les thèmes sur lesquels ils interviennent ; etc.
- les relations entre ces acteurs (coauteurs ; liens de cooccurrence dans les congrès et dans les comités).
La source est volumineuse : pour donner un ordre de grandeur, 574 acteurs sont recensés entre 1906 et 1949. Elle est aussi complexe, notamment parce que son contenu est très hétérogène (article scientifique ; vie de l’association…).
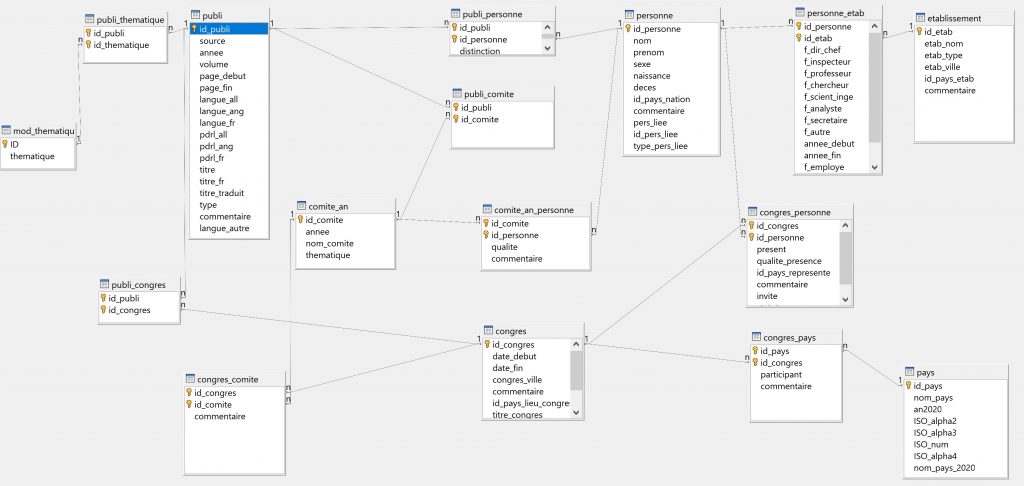
Le traitement quantitatif d’une telle source nécessite la création d’une base de données relationnelle. Pourquoi une base de données « relationnelle » ? Parce que les « entités » qui nous intéressent sont de nature diverse (acteur, article, congrès, comité) et que les relations entre ces entités ne sont pas exclusives et univoques.
Prenons un exemple pour expliciter la nécessité d’une base de données relationnelle : un acteur A a rédigé deux articles (dont l’un, sur la thématique T, coécrit avec un acteur B) et participé à trois congrès. Si nous rentrions ces informations dans un simple tableur (Excel ou Calc par exemple), nous aurions deux solutions. La première : créer une ligne par acteur, au risque de démultiplier les colonnes : il faudrait ainsi une colonne « acteur B » pour indiquer si l’acteur A a coécrit un article ou pas avec l’acteur B ; une colonne « article thématique T » pour indiquer si l’acteur A a rédigé ou non un article sur la thématique T ; etc. Ces colonnes s’appliqueraient à tous les autres acteurs renseignés ; et s’ajouteraient à celles nécessitées par le renseignement de ces autres acteurs… d’où la démultiplication démesurée des variables. La deuxième solution : créer une ligne correspondant à la combinaison acteur-article-thématique ou acteur-congrès. Dans ce cas, et pour ce seul exemple, nous créerions 5 lignes (deux articles et trois congrès). L’usage d’un tel tableur serait alors très délicat, voire impossible : comment connaître rapidement le nombre d’acteurs ? comment retrouver facilement des coauteurs ?
La création d’une base de données relationnelle est donc bienvenue dans ce cas de figure. PROGEDO-Loire a accompagné Anaïs GOT dans la réalisation du Modèle Conceptuel de Données (voir Illustration 1) ; et dans la réalisation d’un formulaire de saisie (voir Illustration 2) avec le logiciel libre LibreOffice Base.
Constituer un formulaire de saisie a plusieurs avantages :
- faciliter la saisie des données en proposant une interface plus explicite, plus intuitive et plus ergonomique que celle d’un tableur (Excel ou Calc) : le chercheur n’a pas à naviguer dans les multiples onglets d’un tableur, ni à rechercher la colonne adéquate parmi des dizaines d’autres ;
- assurer la qualité des données (éviter les erreurs de frappe ou la démultiplication des modalités) en contraignant les informations à saisir. A titre d’exemple, une base de données sans saisie contrainte donne fréquemment, pour la modalité féminine de la variable genre : « F », « femme », « femmes » voire « féminin » ou « Mme ». A l’inverse, une base de données avec saisie contrainte assure l’unicité substantielle de chaque modalité : pour la variable sexe, seules 3 modalités seront possibles (par exemple « H », « F » et « X »).
- économiser la saisie et assurer la qualité des données en évitant de répéter des informations déjà renseignées. Par exemple, pour ne pas répéter 34 fois les informations sur un congrès auquel 34 personnes ont participé, on utilise une liste déroulante des congrès dans le formulaire des personnes, qui permettra de faire automatiquement la liaison entre la personne et un(des) congrès déjà renseigné(s).
- faciliter la saisie en proposant un ordre de saisie choisi par le chercheur – lequel correspondra à son travail de recherche, à la façon dont se présentent ses sources de données… Dans le cas du projet d’Anaïs GOT, nous avons réalisé une « chaîne de formulaires » (voir Illustration 3) permettant d’accéder à chacun des 7 formulaires de la base, à partir des deux sources de données de l’historienne : un compte-rendu de comité (en commençant par le formulaire Comité) ou tout autre publication des PISTA (en commençant par le formulaire Publication).

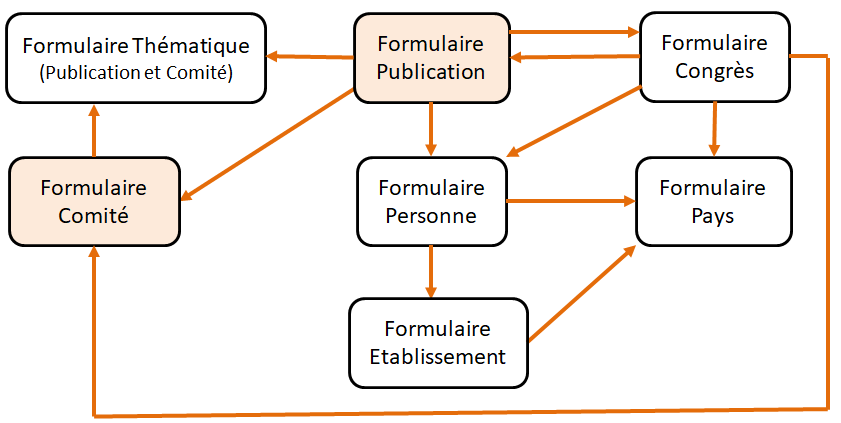
Ce travail – constitution du MCD et du formulaire de saisie – n’a pu être réalisé qu’en contrepartie d’une collaboration étroite entre l’ingénieure PROGEDO-Loire (Aliette ROUX) et la chercheuse (Anaïs GOT). Le MCD comme le formulaire ont subi plusieurs modifications, au fur et à mesure du dépouillement de la source et des questions qu’il posait : informations présentes pour certains numéros de PISTA et pas pour d’autres ; changements d’état d’une entité (exemple : membre d’un comité puis président ; changement de nom d’un comité)… Plutôt que d’essayer de restreindre l’information, nous nous interrogions sur la manière de la traiter, tout en se pliant à l’exigence de rigueur formelle impliquée par le numérique, riche d’intérêts pour l’historien :
« Rester fidèle, le plus possible, au langage de la source n’empêche pas de devoir l’inscrire dans des lignes et dans des colonnes. L’opération n’a rien de trivial ; elle impose le respect de quelques principes facilitant les traitements ultérieurs, mais elle aide aussi à s’interroger sur la source et sur l’objet de recherche »
Claire Lemercier et Claire Zalc, 2008. Méthodes quantitatives pour l’historien, La Découverte ; 120 p., p.36.
Aussi faut-il rappeler la nécessité de l’intervention directe du chercheur pour coder la donnée, comme le soulignent les historiennes Claire Lemercier et Claire Zalc :
« C’est bien souvent à ce moment précis de la recherche, celui de la saisie […] que les savoir-faire, plutôt historiens que « quantitativistes », sont mis à l’épreuve. On ne saurait ici trop insister sur l’importance de cette étape, généralement laissée de côté par les cours et les manuels, alors qu’elle est cruciale. C’est elle qui assure que la construction des données suit les pratiques de critique des sources qui fondent la discipline qu’est l’histoire. Et en pratique, c’est aussi lorsque l’on saisit soi-même ses données que naissent les intuitions qui permettront à la fois de mieux les structurer, de leur poser des questions plus neuves et plus adaptées et, in fine, d’écrire de la bonne histoire ».
Claire Lemercier et Claire Zalc, 2013. « Le sens de la mesure : nouveaux usages de la quantification » in Christophe Granger (éd.), A quoi pensent les historiens ? Faire de l’histoire au XXIe siècle, Autrement, p. 135-164.
[*] European Seed Testing Association en 1921 puis International Seed Testing Association en 1924